Deep Dive: Lambda’s Response Payload Size Limit (1/2)
If you‘ve used AWS Lambda to handle large amounts of data, you have probably also seen this error message:
{
"errorType": "Function.ResponseSizeTooLarge", "errorMessage": "Response payload size exceeded maximum allowed
payload size (6291556 bytes)."
}
Whether you’re having trouble staying within the limit or just want to know more about it, you’ve come to the right place.
In this post, I’ll cover everything you should know to understand the limit, how to measure your response payloads, how any it all fits in with API Gateway. Read on!
What is the limit?
The limit in question is listed on the Lambda quotas page as “Invocation payload (request and response)” and says it’s 6 MB for synchronous invocations.

6 MB (megabytes) should be 6 * 1000 * 1000 or 6,000,000 bytes. Maybe AWS actually mean MiB (mebibyte) and are just writing colloquially?
6 MiB is 6 * 1024 * 1024 or 6,291,456 bytes, which is 100 short of what the error message says. Maybe they reserve 100 bytes for something? Nope, you can use the entire limit.
I can only conclude that someone at AWS accidentally typed a 5 instead of a 4 when writing Lambda’s payload size validation (If you can confirm or deny that, I’d love to hear from you).
Breaking the limit
It’s easy to trigger a ResponseSizeTooLarge error. This simple handler function does so by creating a string containing the letter A repeated 7 million times. Each A is one byte so this is well above the limit.

So if we change it to return “A”.repeat(6291556) it will be okay, right? Wrong. Lambda says the response payload is still too big.
What is the response payload?
The docs for the Invoke action say “the response from the function, or an error object”. More importantly, they show that when Lambda serializes its HTTP response, the payload goes in the body.

Invoke returns JSON and the example handler function returns a JavaScript string. So what does Lambda do with it? It converts it to a JSON string using JSON.stringify.
The relevent code from Lambda’s Node runtime is this:

The point is, Lambda ends up with a JSON string and JSON strings start and end with a double-quote, like "this". That’s two double-quotes. Therefore, our actual response payload is currently 6,291,556 + 2.
If we want to stay within the limit, we need two fewer A's to make room for those double-quotes. Returning “A”.repeat(6291554) makes Lambda happy.
Measuring response payloads
Let’s look at another example function handler.

I’ve prepended a £ symbol and subtracted one A to account for it. Will this work? No, it won’t.
This is because Lambda uses the ubiquitous UTF-8 encoding in its responses. That means A and " are one byte while the £ symbol takes up two bytes. Going down to “£” + “A”.repeat(6291552) fixes the problem.
How can we check the length of a response before returning it? The first step is to convert it to JSON using JSON.stringify (because that’s what Lambda does). Then we need to check the length. Let’s modify the handler to try that.

After invoking this function, I see Payload size: 6291555 in the logs.
But we’re expecting to be using the entire 6,291,556 limit. If we take a look at Lambda’s Content-Length response header, we can see that we are.
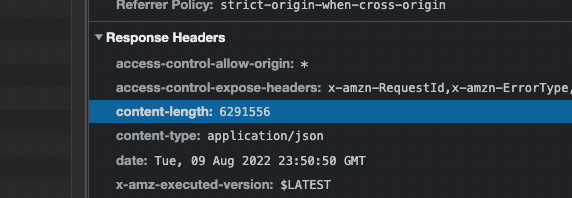
What’s happening? We can make that more obvious by returning just a £ which gives a Content-Length of 4; two bytes for the £ symbol and one each for the double-quotes. JSON.stringify(“£”).length on the other hand gives us a length of 3.
JavaScript string encoding is a whole other story. One that I don’t fully understand. What it boils down to, though, is that string .length generally doesn’t count UTF-8 bytes.
The good news is the TextEncoder class exists and does count UTF-8 bytes! This is the correct and native way to measure a response payload:

API Gateway proxy integrations
API Gateway has a response payload limit of 10 MB. That’s well above Lambda’s limit. Therefore, it’s fair to assume that any payload size problems are caused by Lambda and your code running there.
I’ve modified the example function again to return statusCode and body like API Gateway expects for proxy integrations:

If we run this, we’re right back at the ResponseSizeTooLarge error. Can you guess what is wrong now?
Remember, the Lambda runtime is calling JSON.stringify on whatever your handler returns. That means we’re going to end up with JSON like {"statusCode":200,"body":"..."}.
Even if we set body to be an empty string, the extra quotes, colons, commas, and curly brackets take up bytes (28 to be exact). Therefore, we need to remove some more A’s to account for this.
The formula is 6291556 — 28 = 6291528, where 6291528 is how many A's can fit in the body string. Switch to “A”.repeat(6291528) and everything works.
What about headers?
Have you heard that headers do (or don’t) count toward the payload size limit? The truth is, discussing headers is completely missing the point. I’ll explain.

This function has a response payload size of 35 bytes. You can see that for yourself here.
If I add a header for API Gateway, the size increases to 75 bytes. Again, you can check that here.

Lastly, I’ve added my name to the object. API Gateway doesn’t understand or expect my name, yet the payload size has increased to 91 bytes.

When API Gateway calls Lambda, it does so using normal Invoke, the same way you would. It doesn’t have any backdoor access.
By the time API Gateway receives a response, Lambda has already decided to allow or reject your response payload based on its UTF-8 encoded JSON size.
To put it simply, API Gateway has nothing to do with this.
What about base64 encoding?
It should be obvious by now, but this makes absolutely no difference.
Even though API Gateway will process this response differently, Lambda has no idea what you’re doing. All it sees is an object with three properties, one of which is called body and contains a string. Only you know it’s Base64.
Objects containg Base64 strings will be stringified to JSON and encoded using UTF-8 just like any other return value. The example below is 74 bytes.

Base64 encoding uses 1 byte for every 6 bits of binary data. It also adds padding when the bit stream isn’t divisible by 6. The best thing to do is to Base64 your data and measure it as a string like Lambda does.
While we’re discussing API Gateway
There is an interesting gotcha when working with Lambda, large payloads, and API Gateway: Lambda still returns a 200 status code even when you get a ResponseSizeTooLarge error.
When API Gateway receives that 200 along with the body from the start of this post, it returns a 502 Bad Gateway with a "Internal server error" message. This is the same response API Gatway returns for any user error (for example, if you throw new Error("example");).
The good news is now you know how to measure your response payload and guard against this happening!
Summary
- When the Lambda docs says 6 MB, they mean 6,291,556 bytes.
- The payload size limit is applied by Lambda.
- Lambda doesn’t care who or what called Invoke.
- Lambda calls
JSON.stringifyon your handler’s return value. - Lambda uses UTF-8 encoding in its HTTP responses.
- Some characters (especially emojis) use more than 1 byte.
- Use TextEncoder instead of
"".lengthto accurately check the size of your response in bytes. - When using API Gateway, calculate the size of the whole return object including custom
headers,statusCode, etc. You’ll then know how many bytes can go in thebody. - Base64 uses 1 byte per 6 bits of binary data. Do what Lambda does and convert your data to a Base64 string before calculating its size.
Part 2
This is part 1 of a 2 part series on Lambda’s payload size limits. If you enjoyed this post, you’ll enjoy the second part too:
For more like this, please follow me on Medium, Twitter, and Bluesky.

